High Availability clusters behind a GCP Load balancer
Google Cloud Platform (GCP) Load Balancing is a fully distributed, software-defined managed service. It does not require creating or managing infrastructure components in the GCP environment.
- External load balancers distribute traffic coming from the internet to your Google Cloud Virtual Private Cloud (VPC) network.
- Internal load balancers (ILB) distribute traffic to instances inside of Google Cloud.
In this article, we will discuss a specific scenario related to Internal load balancing.
GCP Internal load balancing is not a “proxy”, and is implemented in virtual networking. It doesn’t terminate connections from clients and open new connections to the back end nodes. Instead, an internal TCP/UDP load balancer routes original connections directly from clients to the healthy back ends, without any interruption.
- There’s no intermediate device or single point of failure.
- Client requests to the load balancer virtual IP address go directly to the healthy back end virtual machines.
- Responses from the healthy back end virtual machines go directly to the clients, not back through the load balancer. TCP responses use direct server return.
This design creates a unique scenario, where the back end nodes need to be accepting traffic on the load balancer’s Virtual IP(VIP) address . This is accomplished in the load balancer design by automatically creating a local host route on all back end nodes with the load balancer VIP.
For most applications that host the same content on all back end nodes and respond to clients in the same way, this works seamlessly. In addition, any traffic that needs to reach a different service or port on the same load balancer gets hair pinned to the same node, which reduces latency of travelling to the load balancer and getting directed to another node.
However..
There are applications that form an “application cluster” with the back end nodes. They publish the service from one node only, and automatically fail over to another node when the active node has an issue. See diagram below showing this scenario:
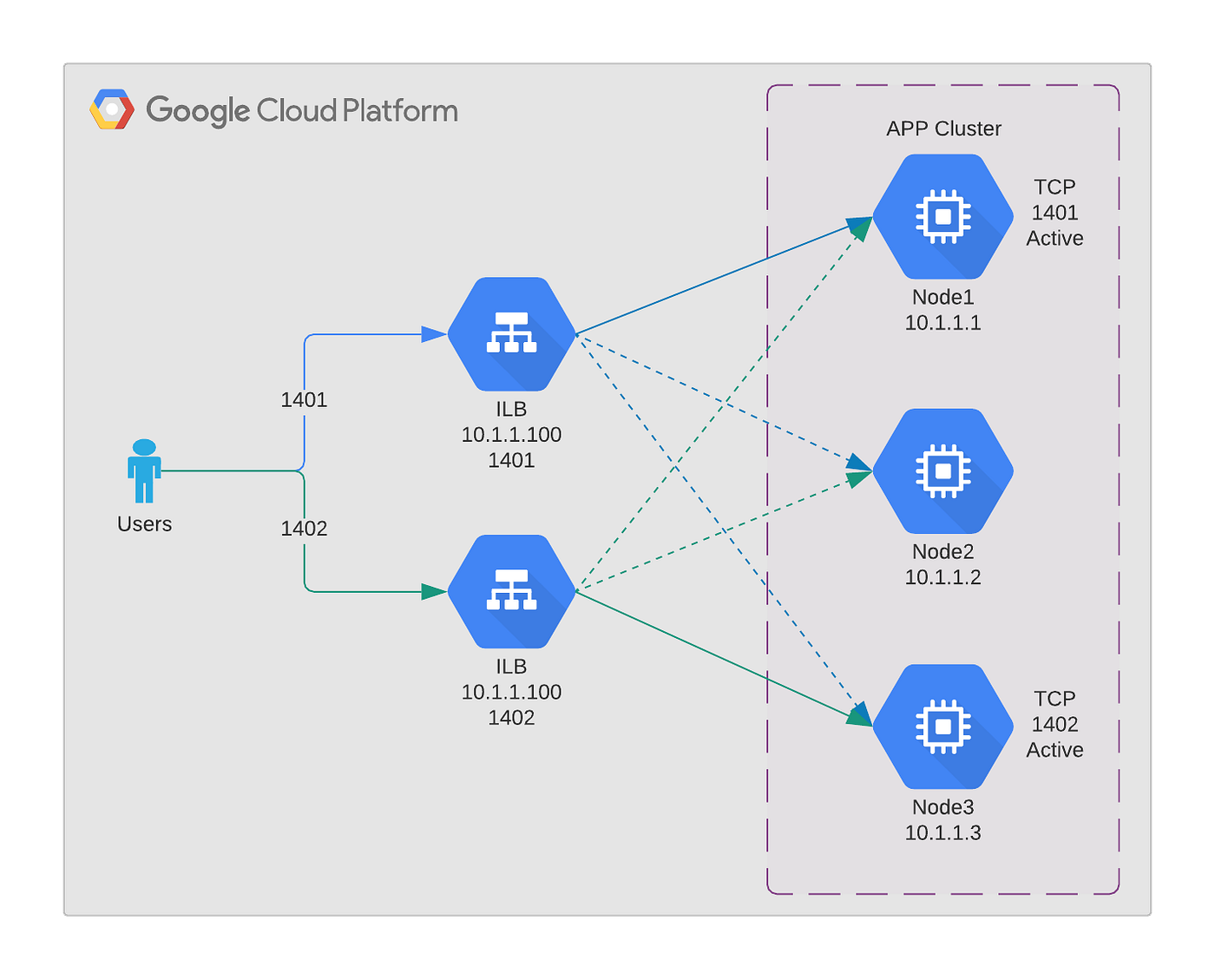
If there is only one active service (for example, an application listening on TCP port 1401), this scenario can be easily handled by having a “floating” IP address between the back end nodes. This can get complicated with multiple services, say TCP ports 1401 and 1402 listening on two different nodes. Now, the number of required floating IPs increase and managing the fail over of these IPs can become challenging.
A load balancer with proper health checks is one way to solve this — even though there is technically no ‘load balancing’, the traffic will always reach the active node based on the health checks. And the same IP address and DNS name can be used to publish all services (e.g., TCP ports) to clients. And this works seamlessly in a traditional proxy load balancer.
In the GCP networking world, where you really are not connecting your virtual machines to a Layer 2 network, gratuitous ARP and other floating IP management methods are not easily achievable.
But, there’s a catch..
With the GCP Load balancer that uses a host route for the VIP on all the back end nodes, this will create an unique problem. In the above example Node 1 is hosting a service on port 1401 and Node 3 is hosting another service on port 1402. If Node 1 needs to reach the service on port 1402, it cannot use the load balancer VIP to reach that, since the traffic routes to itself due to the host route. And since it does not service port 1402, the connection fails. The scenario is shown here:

And for every unique problem, there is a unique solution..
By doing some crafty routing manipulation on the back end nodes, we can direct all traffic from the machine except for it’s own IP addresses to the network. The commands listed below will make this work for the sample design discussed here:
- First, we set the appropriate kernel variable to allow local traffic on the network interface. If this is not set, the kernel will drop external packets to the local IPs as martian packets.
sudo sysctl -w net.ipv4.conf.eth0.accept_local=1- Add a rule to lookup local for all incoming packets via eth0
sudo ip rule add pref 0 iif eth0 lookup local- Add a rule to lookup the local route table (usually pointing to the default gateway) for all traffic not belonging in the primary subnet range. (e.g., primary subnet range is 10.1.1.0/24)
sudo ip rule add pref 0 not to 10.1.1.0/24 lookup local- Add a rule to lookup the local IP table for interface’s primary IP. (e.g., If the interface’s primary IP is 10.1.1.3 - note that this is not the Shared VIP for the ILB)
sudo ip rule add pref 0 to 10.1.1.3 lookup local- You may want to add more rules per alias IP range in primary subnet range. There can be up to 10 such rules.
sudo ip rule add pref 0 to <ALIAS IP RANGE> lookup local- Delete existing local table lookup rule in pref 0. Move this to the bottom of the script if you need connectivity while running the commands below (e.g., manually typing the commands via ssh).
sudo ip rule del pref 0 lookup localThis essentially sends all traffic other than local IP addresses on the backend node to the network which then redirects traffic through the load balancer VIP to the active node for that service.
That traffic flow would look something like:

This routing trick would come in handy for any applications that serve multiple services on different ports and handles the High Availability through an Application clustering feature, but still need a single entry point to the application services through a load balancer.
Some classic examples are HA clusters used by applications like IBM MQ messaging service, Hashicorp Vault and so on..
Thanks for reading, and please post your comments and suggestions below.
